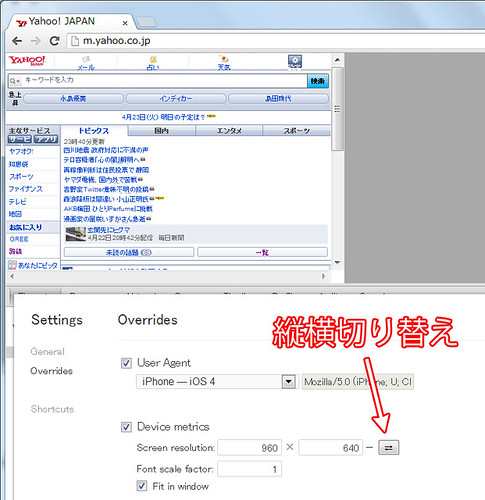
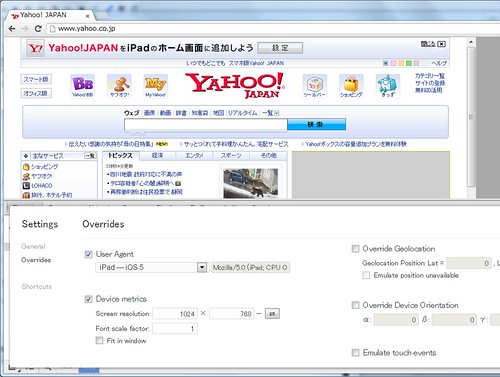
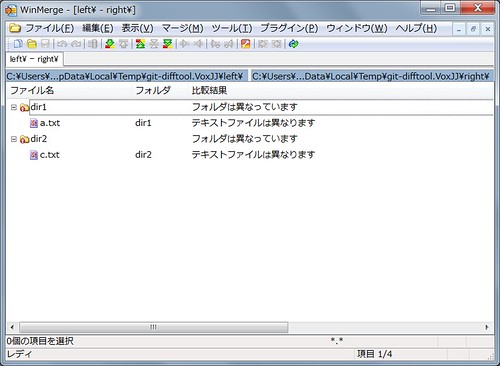
class Hash
# Read array from the supplied hash favouring the singular key
# and then the plural key, and handling any nil entries.
# +hash+ the hash to read from
# +singular_key+ the singular key
# +plural_key+ the singular key
#
# Returns an array
def pluralized_array(singular_key, plural_key)
hash = self
if hash.has_key?(singular_key)
array = [hash[singular_key]] if hash[singular_key]
elsif hash.has_key?(plural_key)
case hash[plural_key]
when String
array = hash[plural_key].split
when Array
array = hash[plural_key].compact
end
end
array || []
end
#!/usr/bin/perl -I/path/to/bugzilla -I/path/to/bugzilla/lib
use strict;
use Bugzilla;
use Bugzilla::User;
use Bugzilla::Status;
use Bugzilla::Bug;
use utf8;
&update_bug(1, "ほげほげ");
# API document: http://www.bugzilla.org/docs/4.2/en/html/api/
sub update_bug {
my ($bug_id, $text) = @_;
# open bug
my $bug = Bugzilla::Bug->new($bug_id);
die $bug->error if defined $bug->error;
# get user
my $user = Bugzilla::User->new({name => 'admin@example.com'});
die 'user not found!!!!' unless defined $user;
# login
Bugzilla->set_user($user);
# comment to the bug
$bug->add_comment($text);
# FIXED
$bug->set_bug_status(Bugzilla::Status->new({name => 'RESOLVED'}),
{resolution => 'FIXED'});
# save to database
$bug->update();
}
Node.js 界で数々の著名モジュールを作ってる TJ Holowaychuk (visionmedia) さんが、さっそく yield を活用するための co というモジュールを作ってるので使わせてもらいます。
こうなるんだぜ。
var co = require('co');
var fs = require('fs');
co(function *() {
var files = yield co.wrap(fs.readdir)('.');
var data = yield co.wrap(fs.readFile)(files[0], 'utf-8');
console.log(data);
});
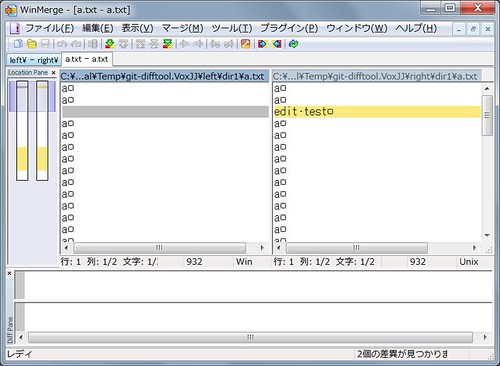
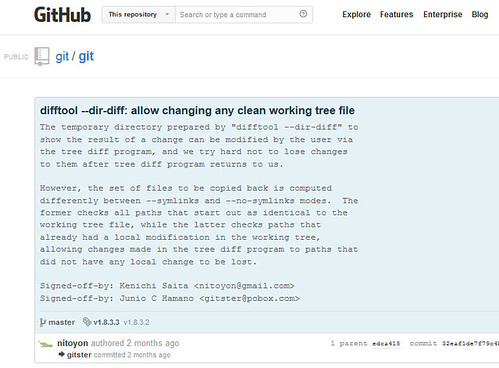
--- git-difftool Sun Jun 2 11:28:06 2013
+++ git-difftool Tue Jul 9 00:42:02 2013
@@ -283,7 +283,7 @@
exit_cleanup($tmpdir, 1);
}
if ($symlinks) {
- symlink("$workdir/$file", "$rdir/$file") or
+ !system("git", "mklink", "$workdir/$file", "$rdir/$file") or
exit_cleanup($tmpdir, 1);
} else {
copy("$workdir/$file", "$rdir/$file") or
@@ -448,7 +448,7 @@
my $indices_loaded = 0;
for my $file (@worktree) {
- next if $symlinks && -l "$b/$file";
+ next if $symlinks;
next if ! -f "$b/$file";
if (!$indices_loaded) {
D3.js is a JavaScript library for manipulating documents based on data. D3 helps you bring data to life using HTML, SVG and CSS. D3’s emphasis on web standards gives you the full capabilities of modern browsers without tying yourself to a proprietary framework, combining powerful visualization components and a data-driven approach to DOM manipulation.
c:\RubyDevKit>ruby dk.rb init
[INFO] found RubyInstaller v2.0.0 at C:/Ruby200-x64
Initialization complete! Please review and modify the auto-generated
'config.yml' file to ensure it contains the root directories to all
of the installed Rubies you want enhanced by the DevKit.
c:\RubyDevKit>ruby dk.rb install
[INFO] Updating convenience notice gem override for 'C:/Ruby200-x64'
[INFO] Installing 'C:/Ruby200-x64/lib/ruby/site_ruby/devkit.rb'
> python easy_install.py
:
Installing easy_install-script.py script to C:\Python27\Scripts
Installing easy_install.exe script to C:\Python27\Scripts
Installing easy_install-2.7-script.py script to C:\Python27\Scripts
Installing easy_install-2.7.exe script to C:\Python27\Scripts
Installed c:\python27\lib\site-packages\setuptools-1.3.2-py2.7.egg
Processing dependencies for setuptools==1.3.2
Finished processing dependencies for setuptools==1.3.2
Pygments
いよいよ Pygments をインストール!
easy_install pygments を実行すればよい。
> easy_install pygments
:
Adding Pygments 1.6 to easy-install.pth file
Installing pygmentize-script.py script to C:\Python27\Scripts
Installing pygmentize.exe script to C:\Python27\Scripts
Installed c:\python27\lib\site-packages\pygments-1.6-py2.7.egg
Processing dependencies for pygments
Finished processing dependencies for pygments
4. Jekyll が動くか確認する!
ここまでくれば導入は完了したはず。動作するかテストしてみよう。
>jekyll new jekyll-test
New jekyll site installed in path/to/jekyll-test.
>cd jekyll-test
>jekyll serve
Configuration file: path/to/test-site/_config.yml
Source: path/to/test-site
Destination: path/to/test-site/_site
Generating... done.
Server address: http://0.0.0.0:4000
Server running... press ctrl-c to stop.```
http://localhost:4000/ を開いて結果が出力されていれば成功。
お疲れ様。